Overview of techniques involved (e.g. 'omics')
2. Genomics
2.1. Introduction to DNA and genetics
The basic process in genetics are:- DNA is transcribed into ‘messenger RNA’ (mRNA). Transcription means that the information from a strand of DNA is essentially copied into a new molecule of mRNA.
- mRNA is then translated into a protein.The information in mRNA is used as a template for building the protein.
This is known as the ‘central dogma’ of molecular biology. It describes a process called gene expression.
DNA transcription and
translation
Figure 1: DNA makes RNA makes protein. Taken from http://www.atdbio.com/content/14/Transcription-Translation-and-Replication
DNA is made up of a double strand of molecules called ‘bases’:
- Each base is attached to another base on the other strand, making a ‘base pair’.
- The bases come in four types. These are given the letters A (adenine), T (thymine), G (guanine) and C (cytosine).
- It is the order of these bases that makes up the DNA sequence. The pairing of the bases links the two strands of DNA together into a double helix shape. A can only link with T, and G can only link with C.
DNA Helix and base
pairs
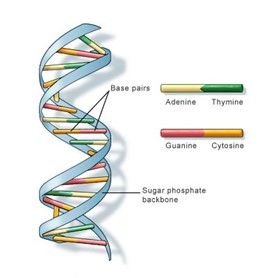
Figure 2: model of DNA, featuring
four chemical ‘letters‘- adenine, thymine, guanine and cytosine, or A, T, G and C. Taken from the US National Library of Medicine.
The sequence of the bases is important because this is the set of instructions the body uses to build proteins. Proteins are used in every cell. They ensure that each part of the body does what it needs to do to allow us to grow and function.
A gene is a length of DNA that contains the code for a particular protein. The structure of any given protein depends largely on the sequence of bases in a gene or genes. Any change to the DNA sequence, such as a genetic variant or mutation, may affect the production of a normal protein. This may in turn affect the normal function of a cell or tissue.
Mike Gilchrist from the UK’s Medical Research Council (MRC) writes:
“Can we get a feel for how much ‘information’ the genome (the entire set of DNA in an individual) contains? In simple terms a good thick airport novel contains about a million letters, and so a library of 3.000 such books would hold the same amount of ‘text’ as the human genome. This would fit easily into bookcases lining one wall of a generously sized living room. If we were to devote our leisure time to reading these ‘books’, and could get through one a week, it would take sixty years to plough through our entire genome..”.
“…our genome sequence is largely made up of repetitive, or uninformative, sequence [that is, not gene sequences], which we think of as having little impact on the day to day running of our bodies. This material is sometimes called ‘junk’ DNA… Our genes, which do most of the useful work, occupy the remaining ‘interesting’ 2% of the genome, and are the key to our biology. We have about 20.000 to 25.000 genes, and each is responsible for making one of the many smaller molecules (mostly proteins) that we need to grow and to function… In addition, the sequence around a gene contains signals which, in concert with other genes, tell the body where and when to produce that gene’s protein. This is the origin of our need as biologists to sequence the genome, as only this way can we begin to understand the functioning of all these genes.”